How do you normalize your data using python? Normalization is another task that you will be performing quite often as a preprocessing step before running your models.
Sometimes, to improve the performance of your model, you will need to change the underlying distribution of the data without necessarily changing the information within the data. Normalization help you do that.
In this article, I will be sharing with you what normalization is, why is it important and how to do it in Python.
What is Normalization?
Normalization is the process of changing the shape of distribution to have a Normal (Gaussian) distribution. It is a very useful technique if we know that the underlying feature distribution is not Normal.
Normalization works by adjusting the values of numerical variables without changing the scale/range of your data. It could be considered as a rescaling technique. But the difference lies in the fact that scaling shrinks/expand the data to fit a particular range whereas normalization does not.
NB: In a lot of articles and literature online, rescaling, standardization and normalization are sometimes used interchangeably and it can be confusing which one is which. Normalization and rescaling almost have the same goal, but I prefer this definition of normalization since it is more natural. For techniques related to standardization transformations, please check out this article on standardization, and for techniques on rescaling transformations, please check out this one.
Why is data normalization important?
Data normalization is important because of the need to change the shape of the data in a more beneficial form. Indeed, some models have been shown to work best if their underlying distribution is normal. Normalization allows us to transform a feature without an underlying normal distribution to a normal one.
Normal distributions are sometimes an assumption for some machine learning models. Ergo, Normalization improves your model’s ability to solve coefficients, which are a measure of how much changing one feature prediction alters another. This is because normalized features make models less sensitive to their scale.
How to normalize your data in Python?
To explore the various techniques used to normalize your data in python, let’s set up a dataset representing a column/feature having a gamma distribution. Depending on the case, there are in general 5 ways to normalize your data, and we will use python to illustrate them.
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
x = stats.gamma.rvs(1, size=5000)+5
sns.set_style("whitegrid")
ax = sns.displot(x, kind = "kde",color = "#e64e4e", height=10, aspect=2,
linewidth = 5 )
ax.fig.suptitle('Original distribution', size = 20)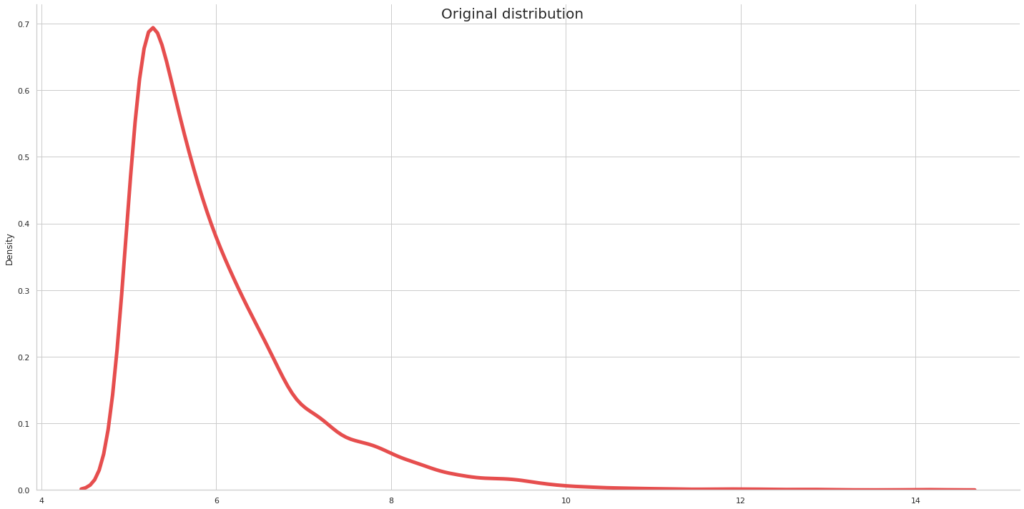
For all the methods described below, I will be using the same distribution above and see the resulting normalized values.
1. BoxCox Transformation
It is my number 1 method to transform and normalize most features. It is represented by the formula below.
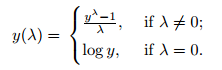
BoxCox transformation takes its name from its authors, statisticians George Box and David Cox. They have developed a procedure that works by identifying an ideal lambda to transform the feature into a Gaussian (normal) form. The lambda is the power at which the values are to be raised and the algorithm searches the best lambda value from -5 to 5.
The Box-Cox does not guarantee normality because there is no normality check included within the algorithm. It only checks for the smallest standard deviation. Nevertheless, the is a very high likelihood that the data is normally distributed when the standard deviation is at the smallest. A normality check (through a probability plot) needs to be performed to be 100% sure.
# Apply Normalization
x_norm, _ = stats.boxcox(x)
# Plot the distribution
ax = sns.displot(x_norm, kind = "kde",color = "#e64e4e", height=10, aspect=2,
linewidth = 5 )
ax.fig.suptitle('Distribution after BoxCox transfomation', size = 20)
2. YeoJohnson
The Yeo-Johnson transformation is another way to normalize your data. It works similarly to the BoxCox transformation but the YeoJohnson creates a more symmetrical distribution and CAN be used with negative values.
from scipy.stats import yeojohnson
x_norm, _ = yeojohnson(x)
ax = sns.displot(x_norm, kind = "kde",color = "#e64e4e", height=10, aspect=2,
linewidth = 5 )
ax.fig.suptitle('Distribution after YeoJohnson transfomation', size = 20)
If the values are strictly positive, then the Yeo-Johnson transformation is the same as the BoxCox power transformation of (y+1). If they are strictly negative, then the Yeo-Johnson transformation is the Box-Cox power transformation of (-y +x), but with power 2-lambda. This allows it to be used for both positive and negative values.
3. Log Transformation
In the log transformation, you can change each value of the feature by a base 2, 10, or a natural log. It is represented with the np.log function.
You should use Log Transformation when you have an original distribution that is skewed. The skewness can be caused by a highly exponential distribution, outliers, etc.
Here’s how to normalize data using log-transformation with python. It’s rather simple.
x_norm = np.log(x)
ax = sns.displot(x_norm, kind = "kde",color = "#e64e4e", height=10, aspect=2,
linewidth = 5 )
ax.fig.suptitle('Distribution after Log transfomation', size = 20)
4. Reciprocal Transformation
In this method, we will simply replace each value with its inverse using (1/x). This method has little effect on the shape of the distribution compared to the other methods and can only be used for non-zero values.
x_norm = 1/x
ax = sns.displot(x_norm, kind = "kde",color = "#e64e4e", height=10, aspect=2,
linewidth = 5 )
ax.fig.suptitle('Distribution after Reciprocal transfomation', size = 20)
5. Square Root Transformation
n this method, we will replace each value of the original with its square root by applying np. sqrt(x) to get the values square root. It has a somewhat noticeable effect on the distribution and can be used on zeros values.
x_norm = np.sqrt(x)
ax = sns.displot(x_norm, kind = "kde",color = "#e64e4e", height=10, aspect=2,
linewidth = 5 )
ax.fig.suptitle('Distribution after Squareroot transfomation', size = 20)
Bonus: Unit Vector Transformation
I mentioned the unit vector transformation because scikit learn has a Normalize function which stands for a unit vector normalization, which can only be applied to rows.
It is a process of scaling individual samples to have a unit form. As per the documentation: “Unit Vector Transformation can be useful if you plan to use a quadratic form such as the dot-product or any other kernel to quantify the similarity of any pair of samples”.
from sklearn import preprocessing
X = [[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]]
X_norm = preprocessing.normalize(X, norm='l2')
X_normarray([[ 0.40824829, -0.40824829, 0.81649658],
[ 1. , 0. , 0. ],
[ 0. , 0.70710678, -0.70710678]])Need this on your data, not a demo dataset?
Tutorials run on clean example data. Production data doesn’t cooperate. When forecasting, segmentation, churn, or LTV modelling has to survive real, messy data and drive an actual decision, that’s data science consulting work. Book a call and tell me what you’re trying to predict.
Feel free to use any information from this page. I’d appreciate it if you can simply link to this article as the source. If you have any additional questions, you can reach out to malick@malicksarr.com or message me on Twitter. If you want more content like this, join my email list to receive the latest articles. I promise I do not spam.
If you liked this article, maybe you will like these too.
Hyperparameter Tuning with Random Search
Hyperparameter Tuning with Grid Search