Hyperparameter tuning is a common task if you do machine learning. You will encounter and perform it multiple times if you plan to improve the performance of your model. In this article, I will be showing you code snippets of how to do hyperparameter tuning with Random Search using SkLearn.
STEP 1. Loading the data for hyperparameter tuning with Random Search?
In the first step, we will be importing the libraries and the data for our experiment. In this case, we will be working with the well-known Boston dataset. It is a regression type of dataset, and it allows learners to practice their regression skills.
To do Random hyperparameter tuning on a problem of regression, we will use the RandomizedSearchCV module from the sklearn.model_selection library. In addition to that, we will import the RandomForestRegressor which is a function in the library used to perform Random Forest regression. We will import helper stats functions to test our various model parameters.
# import random forest, the Random Search Cross Validation
from sklearn import datasets
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform, truncnorm, randint
# get the boston dataset
data = datasets.load_boston()
X = data.data
y = data.targetSTEP 2. Load the model parameters to be tested using hyperparameter tuning with Random Search
In this step, we will set up the various ranges for the model parameters that need to be optimized/tests. During the cross-validation set, a number will be randomly generated within those predefined ranges.
# Load the model parameters to be test
model_params = {
# randomly sample numbers from 10 to 500 estimators
'n_estimators': randint(10,500),
# normally distributed max_features, with mean .5 &sd 0.1,
# between 0 and 1
'max_features': truncnorm(a=0, b=1, loc=0.5, scale=0.1),
# uniform distribution from 0.01 to 0.2 (0.01 + 0.199)
'min_samples_split': uniform(0.05, 0.2)
}STEP 3. Create, initialize and test your model
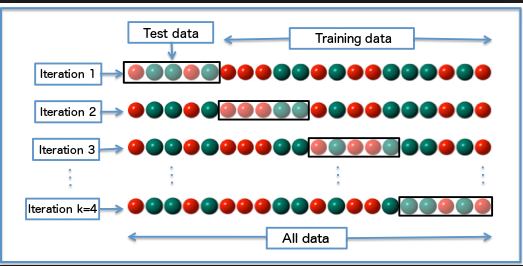
Once you set the range of the hyperparameters, the next step is to initialize the model that we want to run the hyperparameter tuning. In this case, it is a random-forest model. To initialize the random forest model, we will set the test to 100 models. Those models are passed through a 5 fold cross-validation (people use the term k fold validation). A 100 models on a 5 fold cross-validation, means that there are going to be 500 iterations (tests).
K-fold cross-validation is a resampling technique that ensures that every data point from the original dataset has the chance to appear and be used in training and test set. Then, we can fit the RandomizedSearch model to our dataset using the integrated fit method.
# create random forest regressor model
rf_model = RandomForestRegressor()
# set up random search meta-estimator
# this will train 100 models over 5 folds of cross validation (500 models total)
clf = RandomizedSearchCV(rf_model, model_params, n_iter=100, cv=5, random_state=1)
# train the random search meta-estimator to find the best model out of 100 candidates
model = clf.fit(X, y)There you go you have fitted the model to your dataset and the cross-validation is done. Let’s print the best parameters.
pprint(model.best_estimator_.get_params()){'bootstrap': True,
'ccp_alpha': 0.0,
'criterion': 'mse',
'max_depth': None,
'max_features': 0.5561526604307352,
'max_leaf_nodes': None,
'max_samples': None,
'min_impurity_decrease': 0.0,
'min_impurity_split': None,
'min_samples_leaf': 1,
'min_samples_split': 0.05316424856931126,
'min_weight_fraction_leaf': 0.0,
'n_estimators': 327,
'n_jobs': None,
'oob_score': False,
'random_state': None,
'verbose': 0,
'warm_start': False}There you have it. As you can see, there are other parameters that you could have used to tune your model. Depending on your project, you may decide what to tune, or not to tune. This is where your knowledge of math behind the algorithm comes in. The more you know about how an algorithm work, the more familiar you will be with how those hyperparameters affect a model. That way you will be able to filter out what you consider important. Then again, it is not a perfect science, it will simply help you save time.
Why is Randomized Hyperparameter tuning important?
Randomized hyperparameter tuning with random search is the optimal way of finding the best estimator (hyperparameters) for a model. You can think of it as an algorithm that trains and test a range of models by randomly sampling from a predefined set of hyperparameters. Then, the algorithm will pick the best version of the model after training X different versions of the models with various hyperparameter combinations taken at random from your predefined range.
For example, say that you have fined a range a= [2,3,4,5] and b = [7,8,9], and you want to test 4 different models (in the example above, we tested 500). For simplicity, we will use accuracy as a scoring function. So, the model will run for 4 iteration in which the model randomly selects.
- For iter 1, a = 3 and b = 9, and this has an accuracy of 67%.
- For iter 2, a = 5 and b = 9, and this has an accuracy of 68%.
- For iter 3, a = 5 and b = 7, and this has an accuracy of 65%.
- For iter 4, a = 2 and b = 8, and this has an accuracy of 72%.
Therefore, after the model has run every possible combination, it will select a and b as the best hyperparameters since they resulted in a higher score.
It is to be noted that in some literature, random search can be called a meta-estimator. Indeed, it is essentially an algorithm applied to an existing estimator to tune the hyperparameters.
I prefer this method slightly more than Grid Search because Random Search goes over the distribution of parameters instead of a predefined list of values for each hyperparameter. Additionally, searching through distribution allow you to add your logic in the sense that you can draw values from a distribution that could be normal, Poisson, exponential, etc. depending on your interpretation of your problem.
Need this on your data, not a demo dataset?
Tutorials run on clean example data. Production data doesn’t cooperate. When forecasting, segmentation, churn, or LTV modelling has to survive real, messy data and drive an actual decision, that’s data science consulting work. Book a call and tell me what you’re trying to predict.
Feel free to use any information from this page. I’d appreciate it if you can simply link to this article as the source. If you have any additional questions, you can reach out to malick@malicksarr.com or message me on Twitter. If you want more content like this, join my email list to receive the latest articles. I promise I do not spam.
If you liked this article, maybe you will like these too.
Hyperparameter Tuning with Grid Search in Python
How to Split your Dataset to Train, Test and Validation sets? [Python]
Google Analytics: How to get your Top N Products by location?
SQL Data Science: Most Common Queries all Data Scientists should know