I am sure that sometimes you asked how do you choose the right machine learning algorithm for your problem. For every Machine Learning challenge, there exist numerous techniques and models to solve them. For instance, a spam detection classification problem can be tackled using many approaches, involving naive Bayes, regression models, and deep learning approaches such as BiLSTMs.
Having many alternatives is beneficial, but picking which model to apply in production is essential. Although we have many performance indicators to evaluate a model, it is not best to implement every solution for every problem. As a result, it is essential to understand how to choose the best algorithm for a given task.
In this post, we’ll look at the criteria that might help you choose an algorithm that’s right for your project and your specific business needs, as well as some of the finest models to utilize. It will achieve this by considering many criteria that might help you narrow down your options.
Understanding these aspects will assist you in comprehending the objective that your model will accomplish. But first, we need to understand what exactly is a machine learning algorithm? What are the different kinds? So, without further discussion, let’s get started!
What Is A Machine Learning Algorithm?
Machine learning is an algorithm-based approach for evaluating data to find patterns and make correct estimates. ML algorithms, as the name implies, are simply computers that educate in many ways. These are the sorts of ML algorithms that fit into three and a half essential groups.
Every day, humanity generates an increasing amount of data. It derives from many sources, including company data, personal social media content, IoT sensors, etc. Machine learning techniques are used to transform this data into something helpful, such as automating procedures, personalizing experiences, and making complex predictions that human brains cannot achieve on their own.
Given the wide range of jobs that ML algorithms can do, each type specializes in a particular job, taking into account the characteristics of the data you have and the needs of your project. Let’s look at each of the basic categories of ML algorithms and some instances of how they are utilized for the most typical jobs.
What Are The Types Of Machine Learning Algorithms?
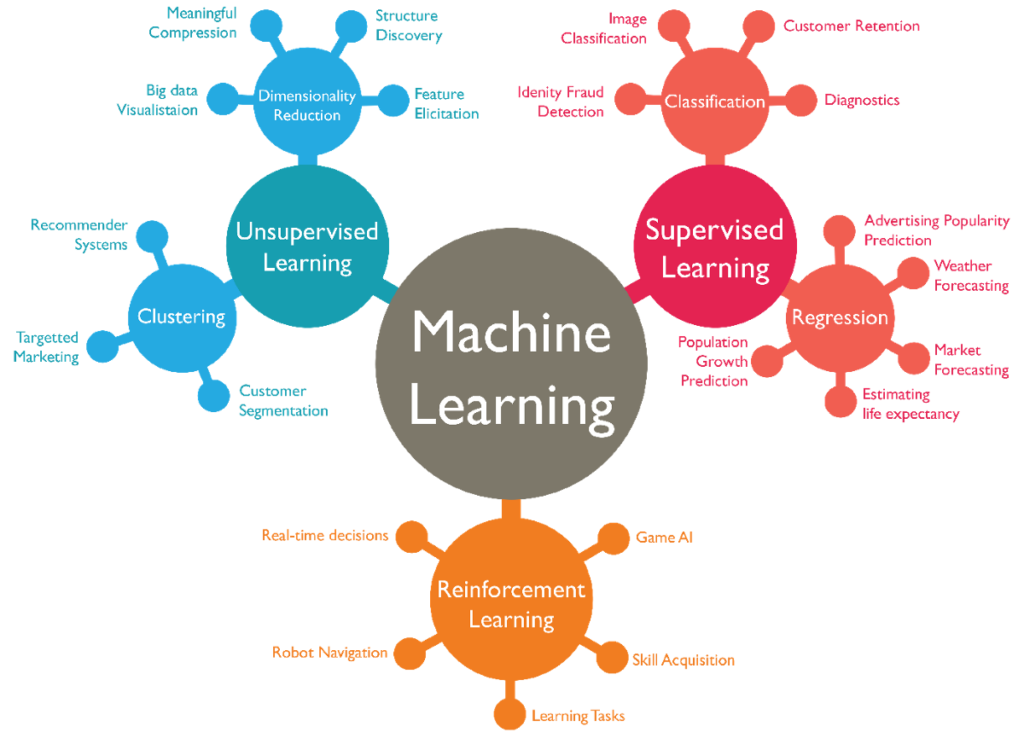
1. Supervised Learning:
The training supervises learning when the model is monitored while it is learning. But what exactly does overseeing a machine involve? That is, you offer the model a range of information made of characteristics and its corresponding label. The result is known as labelled data (one column), while the remaining data (rest of columns), utilized as input features.
Supervised learning further separates into two groups: regressions and classifications, each with its own set of use cases and benefits. Linear models, Nave Bayes, Decision Trees, Support Vector Machines, and Neural Networks are examples of supervised learning algorithms.
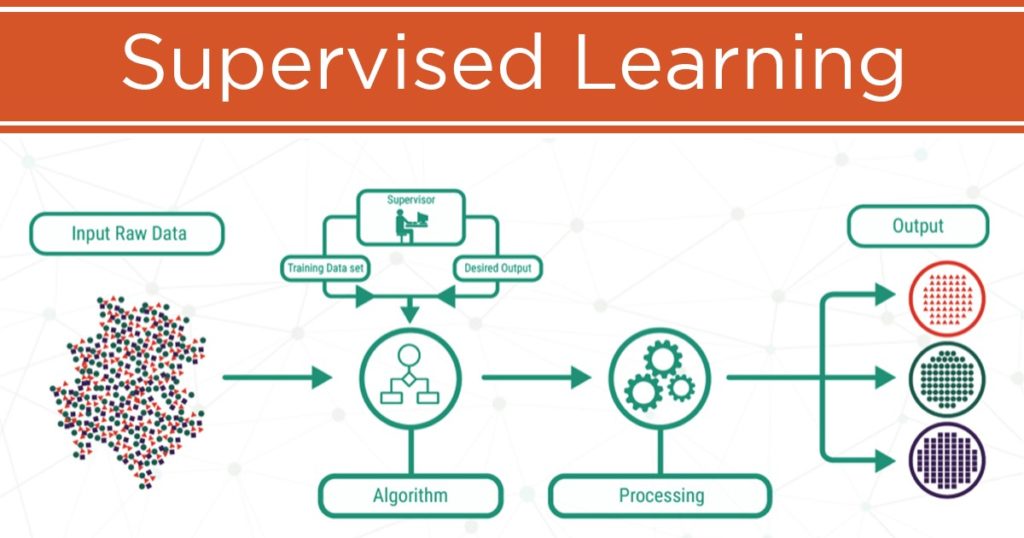
2. Semi-Supervised Learning:
Because of the emergence of semi-supervised learning, the need for large quantities of labelled data for training machine-learning systems may reduce with time.
The technique, as the name implies, combines supervised and unsupervised learning. To perform Semi-Supervised Learning, we need a training set with a small amount of tagged data and a significant number of raw data.
The tagged data is used to partly train a machine-learning model, which is then used to label the unlabeled data, a process known as pseudo-labelling. The model is then trained using the resulting mixture of labelled and pseudo-labelled data.
Semi-supervised learning’s feasibility has subsequently increased by Generative Adversarial Networks (GANs), Machine-Learning Systems that can utilize labelled data to produce wholly new data, which can then train a machine-learning model.
If semi-supervised learning becomes as efficient as supervised learning, then access to massive quantities of computer power may become essential than access to large, labeled datasets for effectively training machine-learning systems.
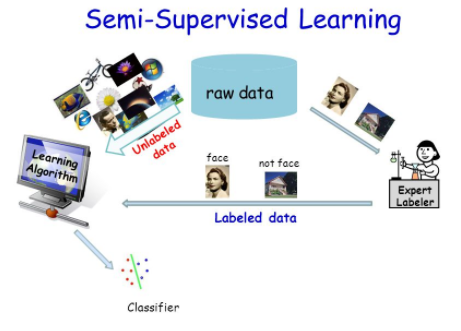
3. Unsupervised Learning:
As the name implies, unsupervised learning requires no assistance from the users for the computer to learn. In the absence of labelled training sets, the computer detects patterns in the data that are not immediately apparent to the human eye. As a result, unsupervised learning is incredibly effective for recognizing patterns in data and assisting us in making judgments.
Unsupervised learning is frequently utilized in clustering issues, with the most often discussed algorithms becoming k-means and hierarchical clustering. On the other side, algorithms such as Hidden Markov models, Self-Organizing Maps, and Gaussian Mixture designs are also frequently utilized.
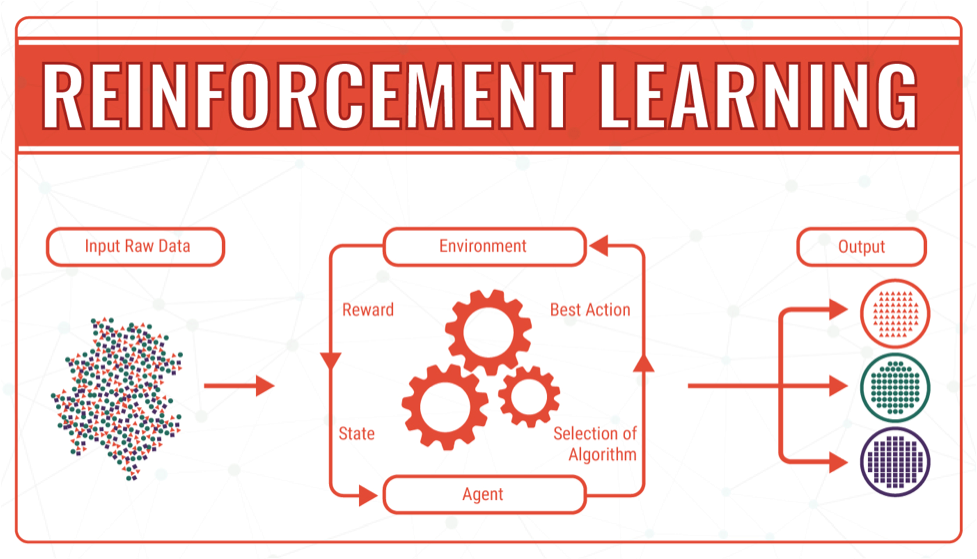
4. Reinforcement Learning:
Reinforcement learning is perhaps the most similar to how people learn. In this situation, the algorithm or agent continuously learns from its surroundings by engaging with it.
Based on its actions, it receives a positive or negative reward. Consider the same scenario of a consumer who has a bank loan. A Reinforcement Learning algorithm analyses a customer’s data and categorizes them.
When a consumer fails to pay, the algorithm receives a positive incentive. If the customer does not default, the agent is charged. In both circumstances, the reason improves the agent’s understanding of the problem and the environment, allowing it to make better judgments. Q-Learning, Temporal Difference, and Deep Uncivil Networks are examples of frequent algorithms.
Reinforcement Learning is perhaps the most difficult to use in a corporate setting, although it widely applies to self-driving vehicles.
How To Choose The Correct Machine Learning Algorithm?
Now, here are the essential considerations when you are about to choose a machine learning algorithm:
1. Type Of Problem
Each Machine Learning algorithm is designed to tackle specific challenges. As a result, it is essential to understand what sort of problem we are working with and what form of algorithms works best for each issue. Don’t go into too much detail, but machine learning methods may divide into three types: supervised, unsupervised, and reinforcement learning. Supervised learning may divide into three categories: regression, classification, and anomaly detection, as we discussed in the previous parts. Once you identify the type of problem you are working with, you can finally make a choice of algorithm based on the type of problem. I wrote an article categorizing said algorithm by type of machine learning problem.
2. Training Time:
The execution time of various algorithms varies. Training time is often proportional to the quantity of the dataset and the target accuracy. Additionally, you have to consider how training time affects your project. If your project is within an application and you do not have the resources to train your model forever, then you should consider using a model that does not require a lot of resources. If however, you are doing a research project, and your want to push the limit of your model, then you can afford a longer training time. Consequently, you will have to think about how training time come into play with your project.
3. Size Of Training Set
This aspect plays a significant role in our algorithm selection. High bias/low variation classifiers advantage over low bias/high variation classifiers with a limited training set since the latter would overfit. However, as the training set expands, low bias/high variation classifiers begin to win since high bias classifiers cannot create correct models. So, you will always have to keep in mind how does overfitting come in at the end. Certain algorithms overfit rather quickly so thinking about how much training data is enough data needs to be done.
4. Accuracy
The needed precision will vary depending on the application. Sometimes an estimate is sufficient, resulting in a significant decrease in processing time. Furthermore, approximation approaches are particularly resistant to overfitting. Setting an accuracy threshold wish rather common. For example, if your client wants an 80% accuracy, then not doing more hyperparameter tuning once the threshold is reached is absolutely fine. Why?
For starters, you will save on computer resources to train model further to improve the accuracy. And additionally, you have the opportunity to decrease the complexity of a model. In a business setting, it is much simpler to explain a linear regression than a Multi-Layer Perceptron to a client. So if a simpler model holds the same accuracy as a more complex one, always cho0se the simpler machine learning algorithm.
5. Number of Features:
Sometimes in datasets, the number of features might be relatively vast compared to the number of data points. It is frequently the case whether it comes to genetics or textual data. Due to the enormous number of characteristics, some machine learning algorithms might get clogged, making training time unfeasible. For example, SVM performance is affected by the number of features. Consequently, if you have a dataset with a lot of features, you may want to use another algorithm such as a Neural Network.
Another way to deal with numerous features is to drop features that do not improve a particular model. Similarly, you can use a dimentionality reduction algorithm as well to reduce the number of features. Thinking about how the number of feautre affect your model is another step to thing about when you chose your machine learning algorithm.
6. Number of Parameters:
The algorithm’s behavior is influenced by parameters such as error tolerance and the number of repetitions. Algorithms with a high number of parameters typically need the best trial and error to discover a successful combination. In simpler terms, the more parameter your model has, the more time it will take to improve the model during hyperparameter tuning. This means that the more parameter a model has, the more combination of values your will need to test in order to find the optimal set of parameters.
Even though having numerous parameters gives greater flexibility, training time and algorithm accuracy may be extremely sensitive to achieving precisely the correct values. So, think about this carefully when you choose your algorithm in machine learning.
7. Linear or not:
Several machine learning methods, including linear regression, regression analysis, and support vector machines, use linearity. These expectations are not necessarily harmful to specific issues, but they reduce efficiency in others.
Despite its risks, linear algorithms are often used as the first line of defense. They are often algorithmically easy and quick to train. And going back to a point I made earlier, if the model works well with a linear model, you do not need to use a more complex one. When you choose your algorithm in machine learning, stick to “easier” algorithms if they work.
Most Common Machine Learning Algorithms
To finish up the article, let’s have a quick look at the most widely used machine learning algorithms out there and their application in your choice of machine learning algorithms. Compare the description of the algorithm below to the logic presented in the previous chapter to make your choice.
Technology has improved sufficiently to allow the development of algorithms that enable machine learning. It resulted in automatic replies, enhanced data processing, and trend forecasting. The following is a list of the most widely used machine learning algorithms.
Linear Regression
Linear regression is a statistical approach for summarising and investigating connections between two continuous variables: The independent variable, indicated X, is one variable. The other variable, shown by y, is the dependent variable.
Linear regression choose a single independent variable X to describe or forecast the value of the dependent variable Y. In contrast, multiple regression takes two or more independent variables to determine the outcome using a loss function, including mean squared error (MSE) or mean absolute error (MAE).
Despite its simplicity, this method performs exceptionally well when faced with thousands of characteristics, such as a bag of words or n-grams in natural language processing. More complicated approaches suffer from overfitting many characteristics and do not have large datasets, whereas linear regression do not suffer as much of this overfitting problem. However, if features are unnecessary, it becomes unstable.
[caption id=“attachment_3044” align=“aligncenter” width=“1024”] Linear regression[/caption]
Linear regression[/caption]
Logistic Regression
Because logistic regression uses binary classification, the tag outcomes are also binary. It takes a linear combination of data and implements a non-linear function, resulting in a very compact neural network instance.
Logistic regression allows you to regularise your model in many ways, and you shouldn’t have to worry about your features link as much as you do in Naive Bayes. You also have the best probabilistic interpretation, and unlike decision trees or SVMs, you can quickly change your model to bring in new data.
Consider if you’d like a probabilistic framework or if you expect to get more training data in the future and want to incorporate it into your model rapidly. Logistic regression is not only a black-box approach; it may also assist you in understanding the fundamental elements behind the prediction.
[caption id=“attachment_3045” align=“aligncenter” width=“1024”] Logistic Regression[/caption]
Logistic Regression[/caption]
Decision Trees
Single trees are rarely utilized, but they may provide incredibly efficient algorithms such as Random Forest or Gradient Tree Boosting when combined with many others.
Decision trees handle characteristic interactions well, and because they are non-parametric, you don’t even have to worry about anomalies or whether the data is conditionally independent. One problem is that they do not enable online learning, which means you must rebuild your tree whenever new instances appear.
Another problem is that they are prone to overfitting; however, ensemble approaches like random forests come in. Decision Trees may potentially consume a significant amount of memory.
Trees are the best tools for assisting you in making judgments such as investment decisions, customer churn, build VS. buy decisions, bank loan defaulters, and sales result in qualifying.
[caption id=“attachment_3042” align=“aligncenter” width=“600”] Decision Trees[/caption]
Decision Trees[/caption]
Random Forest
Random Forest is a collection of decision trees. With big data sets, it can tackle both regression and classification issues. It also aids in the identification of the most significant factors among hundreds of input variables.
Random Forest is highly scalable to any number of dimensions and produces typically satisfactory results.It expands marvelously well to any data size, even with minimum understanding of the data itself.
It is one of the most straightforward applications and popular machine learning algorithms that solves many problems. However, using Random Forest might be sluggish, and it is not feasible to iteratively modify the resulting models.
[caption id=“attachment_3048” align=“aligncenter” width=“592”] Random Forest[/caption]
Random Forest[/caption]
Naive Bayes
It is a classification algorithm based on Bayes’ theorem that is simple to implement and is especially helpful for large datasets. In addition to its simplicity, Naive Bayes has been shown to beat even the most advanced classification systems. When CPU and memory resources are limited, Naive Bayes is an excellent solution.
Naive Bayes is quite basic; you perform a series of counts. If the NB assumption of independence is correct, a Naive Bayes classifier will intersect faster than discriminative models like regression models, using fewer training samples.
Even if the NB assumption is not valid, an NB classifier typically performs admirably in practice. If you want something quick and easy that performs well, this is a good choice. Its main downside is that it cannot learn how features interact with one another.
[caption id=“attachment_3046” align=“aligncenter” width=“397”] Naive Bayes[/caption]
Naive Bayes[/caption]
K-Means:
Sometimes you don’t recognize any labels, and your purpose is to give labels based on the characteristics of objects. It refers to as Clustering. Clustering methods may be employed when you or many users wish to separate the data into specific groups based on specific common qualities.
The main problem is that K-Means require advanced knowledge of how many clusters will exist in your data, which may necessitate a large number of trials to imagine the optimal K number of clusters to define. To decrease the time it takes to find the optimal number of clusters, we can use the elbow method.
[caption id=“attachment_3054” align=“aligncenter” width=“561”] K-Means[/caption]
K-Means[/caption]
k-Nearest Neighbors (kNN):
It applies to both classification and regression issues. However, in the industry, it is more commonly employed in clustering. The K nearest neighbors method is a simple algorithm that maintains all existing examples and classifies new instances based on the majority vote of its k neighbors. The case allocated to the class is the most frequent among its K nearest neighbors as determined by a distance function.
These distance functions can be Euclidean, Minkowski, Manhattan, or Hamming. The first three functions are used for continuous variables, while the fourth (Hamming) uses for categorical data. If K is equal to one, the case allocates to the class of its closest neighbor. Choosing K might be difficult at times while executing kNN modeling.
KNN is simply applicable to your everyday life. If you want to discover more about a person about whom you know nothing, you may find out about his close acquaintances and the circles he frequents and acquire access to their information!
[caption id=“attachment_3043” align=“aligncenter” width=“500”] KNN[/caption]
KNN[/caption]
Support Vector Machines:
SVM exploits hyperplanes to distinguish two points with distinct labels (Xs and Os). When straight things can not divide the points, it has to transfer them to a higher dimensional space where they can be divided by consecutive things (kernel trick). It appears to be a curving line in the original space, but it is a straight item in a much higher dimension space.
SMVs are know to be quite efficient on a small dataset, and can be used for both regression or classification. However, they are not highly scalable and performs poorly on large dataset since more ressources are required for them to run.
[caption id=“attachment_3057” align=“aligncenter” width=“1024”] SVM (Wikipedia)[/caption]
SVM (Wikipedia)[/caption]
Neural Networks:
A neural network represents artificial intelligence. The core idea behind a neural network is to replicate many tightly linked brain cells within a computer to teach it to learn, identify patterns, and make decisions in a human-like manner. The remarkable thing about a neural network is that it does not need to be explicitly programmed to learn: it learns independently, just like a brain.
The inputs are on one side of the neural network. It may be a photograph, drone data, or the current status of a Go board. On the other side, there are the neural network’s desired outputs. There are nodes and connections among them between each one. Based on the inputs, the strength of the connections decides what output is required. Nodes are series of weights with are changed through activation functions and updated through a process called backprogagation.
Neural Networks are quite robust algorithm that perform very well in a diverse range of tasks. Personnally, they are what makes machine learning “learn” providing highly accurate results. The disadvantages is that they are quite complex (structurally and numerically) which makes it hard to explain certain unknown behavior. They are as well hardware dependent. It is a good algorithm to go for when you choose an algorithm in a machine learning project.
[caption id=“attachment_3047” align=“aligncenter” width=“512”] Neural Networks[/caption]
Neural Networks[/caption]
Final Words on How to Choose an Algorithm in Machine Learning
I hope that above-suggested methods will be of assistance when you choose your machine learning algorithm. I understand that it is difficult to determine which method would perform best for your application. Truth be told, it comes with experience. But the above I simple guidelines that would make the process slightly easier.
As a result, when your choose your algorithm in machine learning, I advised you that you work iteratively. Test the input data with all of them and then analyze the algorithm’s performance to choose the best among the selected choices.
Furthermore, to provide a great solution to a real-world problem, you must be aware of rules and regulations, business requirements, stakeholders’ concerns and possess great skill in applied mathematics.
If you made this far in the article, thank you very much.
I hope this article on causality in machine learning was of use to you.
Feel free to use any information from this page. I’d appreciate it if you can simply link to this article as the source. If you have any additional questions, you can reach out to malick@malicksarr.com or message me on Twitter. If you want more content like this, join my email list to receive the latest articles. I promise I do not spam.
If you liked this article, maybe you will like these too.
Why is Deep learning called Deep?
Type of Machine Learning Algorithms: The Complete Overview
Gradient Descent in Neural Network. A Gentle Introduction.
How is Machine Learning Used in Influencer Marketing?
SQL Data Science: Most Common Queries all Data Scientists should know
Need this on your data, not a demo dataset?
Tutorials run on clean example data. Production data does not cooperate. When forecasting, segmentation, churn, or LTV modelling has to survive real, messy data and drive an actual decision, that is data science consulting work. Book a call and tell me what you are trying to predict.