Machine learning is done through the use of algorithms. Indeed, each type of Machine Learning algorithms has its particularities and applies to specific situations. In this post, we will explore the different type of machine learning algorithms and their respective characteristics.
In later posts, I will go into detail about each type of machine learning algorithms. If you have not done so yet, do subscribe to my mailing list to keep being posted.
Type of Machine Learning Algorithms
There are three categories of machine learning algorithms: supervised, unsupervised, and reinforcement learning algorithms, which have an ever-increasing number of subtypes.
The majority of machine learning algorithms employ supervised learning methods, which are different due to labelled data with both input (x) and output (y) variables.
As the teacher, you are aware of the correct answer(s) and monitor the algorithm because it makes predictions based on the training data. You make modifications as needed until the algorithm achieves a sufficient degree of execution.
Although there are several supervised machine learning algorithms, the most often utilized are as follows:
- Linear regression
- Logistic regression
- Decision tree
- Random forest classification algorithm
Unsupervised machine learning methods are used to uncover common qualities and distinguishing patterns in unstructured data. Because this sort of ML technique does not require prior training or labelled data, it is free to investigate the information’s structure.
Unsupervised machine learning algorithms, like supervised machine learning algorithms, come in various flavours, such as kernel approaches and k-means clustering. Machine learning algorithms include:
Regression Algorithm
- Linear regression
- Logistic regression
- Multiple Adaptive Regression (MARS)
- Local scatter smoothing estimate (LOESS)
Instance-Based Learning Algorithm
- K — proximity algorithm (kNN)
- Learning vectorization (LVQ)
- Self-Organizing Mapping Algorithm (SOM)
- Local Weighted Learning Algorithm (LWL)
Regularization Algorithm
- Ridge Regression
- LASSO(Least Absolute Shrinkage and Selection Operator)
- Elastic Net
- Minimum Angle Regression (LARS)
Decision Tree Algorithm
- Classification and Regression Tree (CART)
- ID3 algorithm (Iterative Dichotomiser 3)
- C4.5 and C5.0
- CHAID(Chi-squared Automatic Interaction Detection()
- Random Forest
- Multivariate Adaptive Regression Spline (MARS)
- Gradient Boosting Machine (GBM)
Bayesian Algorithm:
- Naive Bayes
- Gaussian Bayes
- Polynomial naive Bayes
- AODE(Averaged One-Dependence Estimators)
- Bayesian Belief Network
Kernel-Based Algorithm
- Support vector machine (SVM)
- Radial Basis Function (RBF)
- Linear Discriminate Analysis (LDA)
Clustering Algorithm
- K — mean
- K — medium number
- EM algorithm
- Hierarchical clustering
Association Rule Learning:
- Apriori algorithm
- Eclat algorithm
Neural Networks
- Sensor
- Backpropagation algorithm (BP)
- Hopfield network
- Radial Basis Function Network (RBFN)
Deep Learning
- Deep Boltzmann Machine (DBM)
- Convolutional Neural Network (CNN)
- Recurrent neural network (RNN, LSTM)
- Stacked Auto-Encoder
Dimensionality Reduction Algorithm:
- Principal Component Analysis (PCA)
- Principal component regression (PCR)
- Partial least squares regression (PLSR)
- Salmon map
- Multidimensional scaling analysis (MDS)
- Projection pursuit method (PP)
- Linear Discriminant Analysis (LDA)
- Mixed Discriminant Analysis (MDA)
- Quadratic Discriminant Analysis (QDA)
- Flexible Discriminant Analysis (FDA)
Integrated Algorithm
- Boosting
- Bagging
- AdaBoost
- Stack generalization (mixed)
- GBM algorithm
- GBRT algorithm
- Random forest
Linear Regression
Linear regression is a statistical approach in which the value of the dependent variable is predicted using independent variables. A connection is formed by mapping the dependent and independent variables on a line known as the regression line and is represented by the equation
$Y= aX + b$
Where Y= Dependent variable (e.g weight).
X= Independent Variable (e.g height)
b= Intercept and a = slope.
Logistic Regression
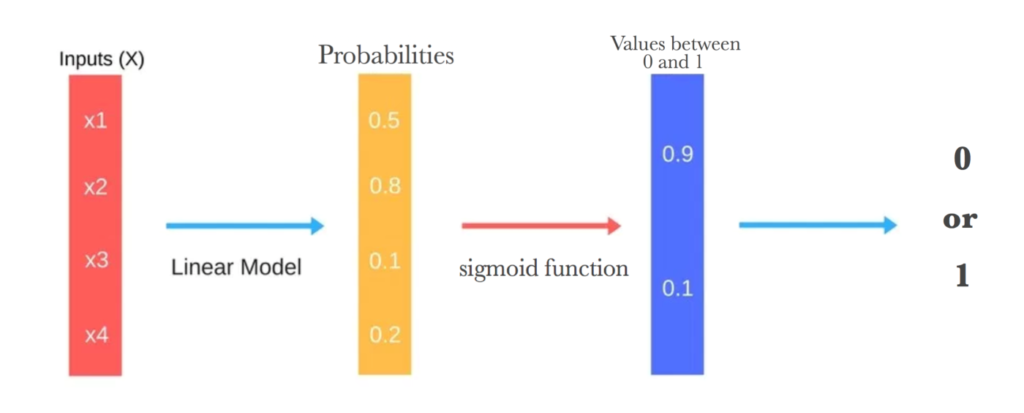
In logistic regression, we have a large amount of data that must be classified using an equation. This approach is used to extract the discrete dependent variable from a group of independent variables. Its purpose is to identify the optimal set of parameters for a given collection of parameters.
In this classifier, each characteristic multiplies by weight before being combined. The result is then handed to the sigmoid function, which generates the binary output—the coefficients for predicting a logit transformation of the probability produce via logistic regression.
Decision Tree
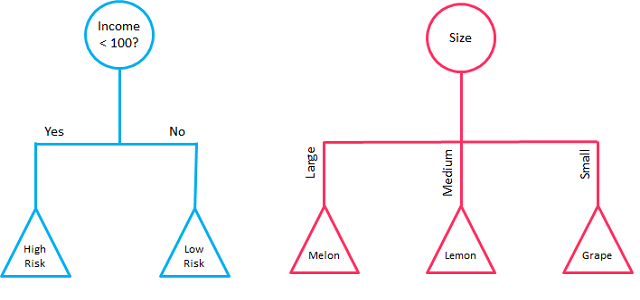
It’s a supervised learning algorithm. Decision trees, which have a tree-like structure, can be used for classification and regression. The best attribute of the dataset is placed at the root of a decision tree-building algorithm, and then the training dataset is divided into subsets.
Data splitting determines the characteristics of the datasets. This method is repeated until the data has been categorized and a leaf node is found at each branch. The information gain may compute to determine which feature provides the most information.
Decision trees are used to create a training model that predicts the class or value of a target variable.
Support Vector Machine:
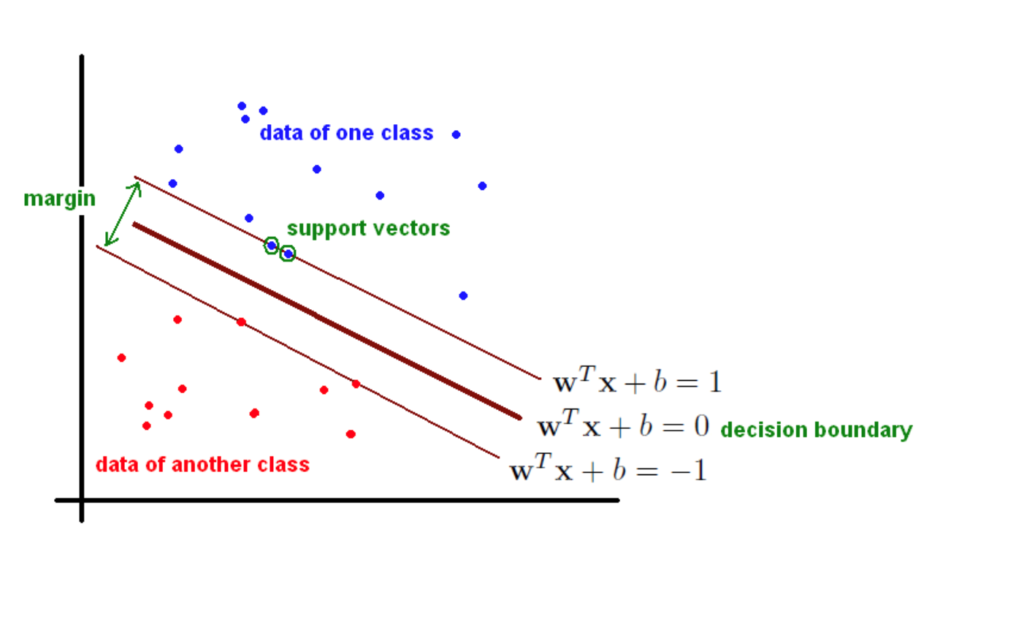
An example of a binary classifier is a support vector machine. The n-dimensional plane is used to depict raw data. A separating hyperplane is drawn to divide the dataset. The ideal hyperplane is the line drawn from the centre of the line separating the two nearest data points of distinct categories. This optimized separation hyperplane optimizes the training data margin. New data may be classified using this hyperplane.
Naive-Bayes:
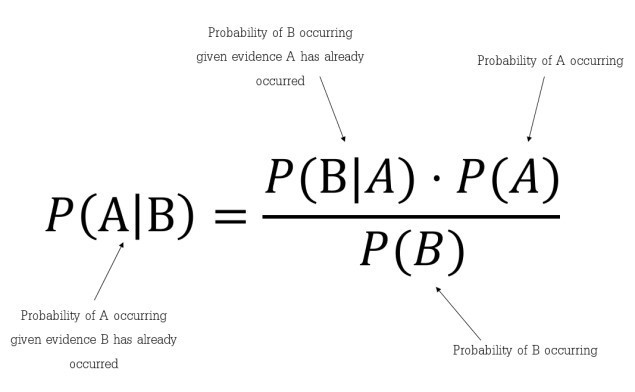
It is a classifier construction methodology based on the Bayes theorem that applies even more complicated classification algorithms. It learns the probability of an object with given characteristics belonging to a specific group or class.
In a nutshell, it’s a probabilistic classifier. The presence of any character in this strategy is independent of the presence of another characteristic. It only requires a small quantity of training data for classification, and all terms may precompute, making division simple, fast, and efficient.
K-Nearest Neighbour (KNN)
This approach is utilized for classification as well as regression. It is one of the most basic machine learning algorithms. It saves the examples, and when new data is received, it compares it to the majority of the k neighbours with whom it shares the best similarities. KNN creates predictions straight from the training dataset.
 Source: DataCamp
Source: DataCamp
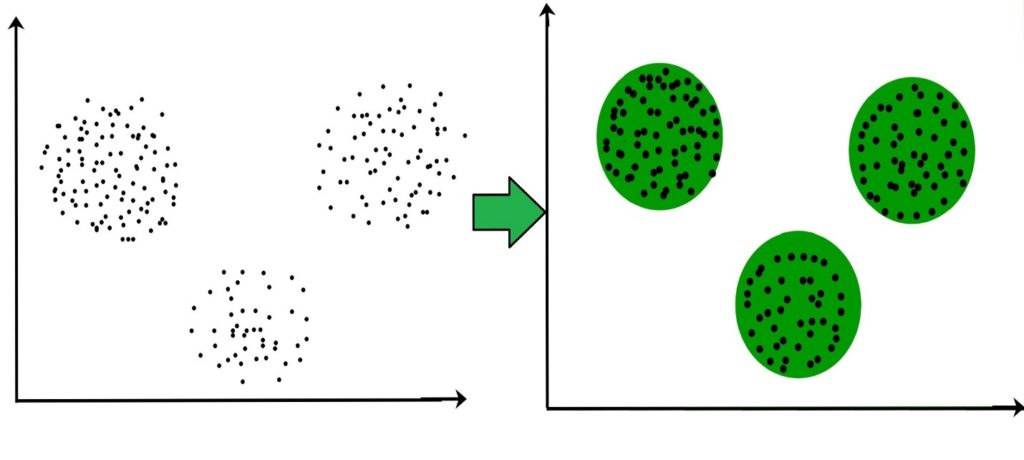
K-Means Clustering
It is an unsupervised learning algorithm that is used to circumvent the clustering constraint. The datasets are initially partitioned into clusters using Euclidean distance. Assume you have k clusters, and each group has a centre.
These centres should be wide apart, and each point is reviewed and added to the nearest cluster in terms of Euclidean distance to the nearest mean until no end remains to wait.
For each new entry, a mean vector recalculates. Iterative relocation carries out until proper clustering achieve. Thus, the process of reducing the objective squared error function repeats by establishing a loop.
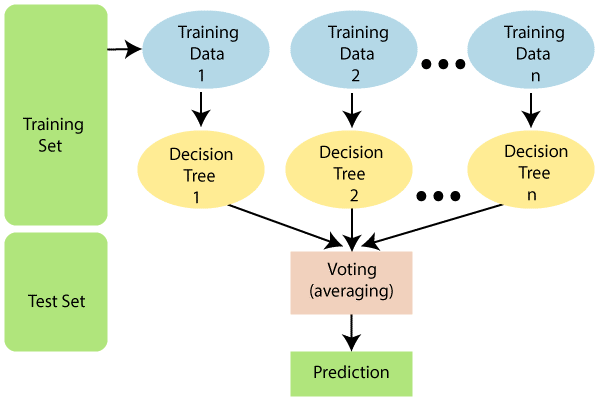
Random Forest
It is a classification method that supervises. A random forest algorithm, which is a collection of numerous classification trees, is formed by a large number of decision trees taken together. It may \use for both classification and regression.
Each decision tree has a rule-based system. The decision tree algorithm will contain a group of rules for the provided training dataset with targets and features. Unlike decision trees, there is no need to compute knowledge gain to discover the root node in a random forest.
It predicts the conclusion using the rules of each randomly generated decision tree and records the expected outcome. It also computes the vote for each desired target. As a result, the random forest algorithm considers the forecast with the highest number of the poll to be the final prediction.
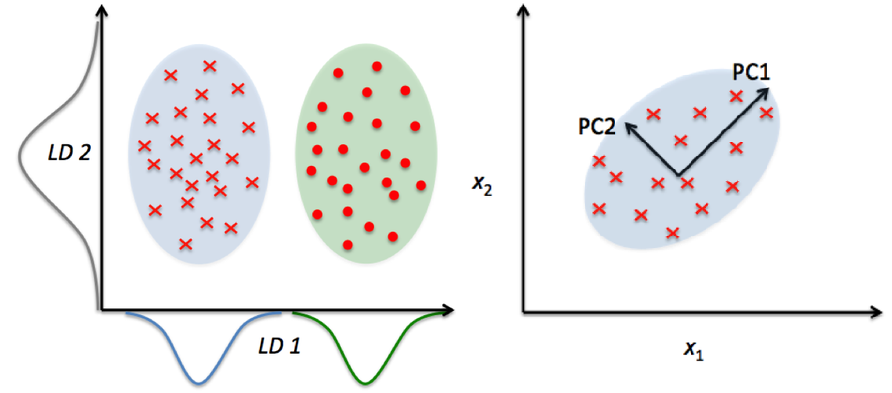
Dimensionality Reduction Algorithms
It is employed to minimize the number of random variables by finding certain primary variables. Dimensionality reduction methods include feature extraction and feature selection.
Principal component analysis (PCA) is used to extract relevant factors from a large set of variables. It takes out the collection of low-dimensional characteristics from high-dimensional data. It is primarily employed when you have more than three dimensions of data.
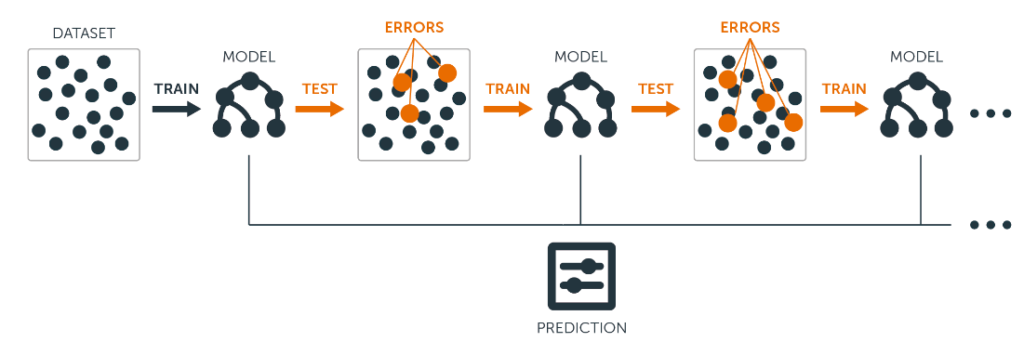
Gradient Boosting And Ada Boost Algorithms:
The gradient boosting algorithm is a classification and regression technique. AdaBoost only picks characteristics that increase the model’s prediction capability.
It works by selecting a fundamental method, such as decision trees, then improving it repeatedly by accounting for erroneously categorized samples in the training set. Both algorithms are used to improve the prediction model’s accuracy.
Machine Learning Algorithms Pros And Cons:
The benefit of ML algorithms over classical statistics is their capacity to digest massive amounts of data fast and produce more accurate predictions based on this incoming data. As a result of these projections, business intelligence insights are helpful in decision-making.
Machine learning algorithms can also automate and enhance a wide range of simple tasks, which helps expedite company operations and save costs. There are several commercial uses for ML technology. However, like with any beautiful thing, machine learning has disadvantages and obstacles.
There is always some prejudice involved when somebody makes a judgment. For example, while deciding where to have dinner and with whom, several aspects come into play: where that person ate before, the time of day, the mood, and chat (or not chat) during dinner. Most of the time, the replies will include some prejudice based on prior experience.
Bias may also be a concern with machine learning algorithms. On the one hand, large volumes of information eliminate some prejudice since it becomes insignificant and is forgotten during the other information.
However, if your initial training dataset is skewed, then all of your findings will have a bias too. This situation is when machine learning fails. When working with data and training your ML algorithms, you must be mindful of additional hurdles. They are not an issue in and of itself, but they consider when implementing machine learning algorithms into business operations.
Final Words on the type of Machine Learning Algorithms:
The large datasets that data scientists acquire are organized, analyzed, and reported. Data can originate from any industry, and it is their responsibility to forecast and plan for the future.
While data scientists have various tools to assist them in examining this data, machine learning techniques help them gain meaningful insights faster. As the amount of data collected throughout the world grows and new algorithms are developed, data science and machine learning areas will need to expand to keep up.
Need this on your data, not a demo dataset?
Tutorials run on clean example data. Production data doesn’t cooperate. When forecasting, segmentation, churn, or LTV modelling has to survive real, messy data and drive an actual decision, that’s data science consulting work. Book a call and tell me what you’re trying to predict.
Feel free to use any information from this page. I’d appreciate it if you can simply link to this article as the source. If you have any additional questions, you can reach out to malick@malicksarr.com or message me on Twitter. If you want more content like this, join my email list to receive the latest articles. I promise I do not spam.
If you liked this article, maybe you will like these too.
How to Organize your Machine Learning Project [ML Project Planning]
How to use Scikit learn in a Machine Learning Project for Beginner? [Sklearn Tutorial]
A Gentle Introduction to Data Science Presentation (Storytelling)
SQL Data Science: Most Common Queries all Data Scientists should know