Gradient Descent is a term that you will often hear in Neural Network. Indeed, the optimization/learning phase of Neural Network (backpropagation) use gradient descent as a method to update the various weight. Gradient descent in Neural Networks is quite common and it is one of the first things to learn during your machine learning journey. In this article, I will simply give you a brief overview of what is gradient descent and what are some gradient descent variations.
Gradient Descent Algorithm
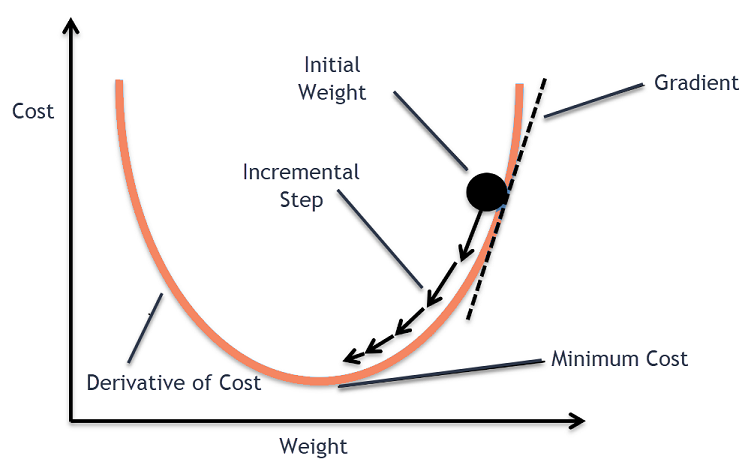
Gradient Descent is an optimization approach in Machine Learning that may identify the best solutions to a wide range of problems. It operates by iteratively tweaking the parameters to minimize the cost function.
The learning rate determines the size of the steps, which is an essential parameter in this method. If the learning rate is low, the algorithm will have to go through many iterations before it can converge, which will take a very long time.
However, if the learning rate is very high, the method will split with greater values, which will aid in the discovery of a good solution. When employing a gradient descent technique, make sure that all features have the same scale; otherwise, the process will take a long time to converge.
Variants Of Gradient Descent
Gradient descent has several forms depending on how much of the data is utilized to generate the gradient.
The primary cause for these differences is computing efficiency. A dataset may contain millions of data points, making computing the gradient throughout the whole dataset computationally tricky.
Batch Gradient Descent:
For the whole training data set, batch gradient descent computes the cost function gradient for parameter W. Batch gradient descent may be exceedingly slow. It would help if you calculated the gradients for the whole dataset to execute a single parameter update.
Stochastic Gradient Descent (SGD):
The gradient for each update is computed using a single training data point x in stochastic gradient descent (SGD). The gradient produced in this manner is a stochastic approximation to the gradient produced using the whole training data.
Each update is now considerably faster to calculate than in batch gradient descent, and you will continue in the same general direction over many updates.
*stochastic means random. Scientist just love their complicated words
Mini-Batch Gradient Descent:
In mini-batch gradient descent, the gradient calculates for each little mini-batch of training data. That is, you divide the training data into tiny groups initially. Each mini-batch receives one update.
M is frequently in the 30–500 range, depending on the situation. Mini-batch GD is commonly employed because computational infrastructure — compilers, CPUs, and GPUs — are frequently tuned for vector additions and vector multiplications.
From above, SGD and mini-batch GD are the most popular.
In most cases, you make numerous rounds over the training data until the termination requirement is reached. Each pass refers to an era. Also, because the update phase in SGD and mini-batch GD is significantly more computationally efficient, you often run 100s-1000s of updates between checks for termination conditions being satisfied.
 Performance of each variant to reach a Global Minimum
Performance of each variant to reach a Global Minimum
If you made this far in the article, thank you very much.
I hope this information was of use to you.
Feel free to use any information from this page. I’d appreciate it if you can simply link to this article as the source. If you have any additional questions, you can reach out to malick@malicksarr.com or message me on Twitter. If you want more content like this, join my email list to receive the latest articles. I promise I do not spam.
If you liked this article, maybe you will like these too.
How to Organize your Machine Learning Project [ML Project Planning]
How to use Scikit learn in a Machine Learning Project for Beginner? [Sklearn Tutorial]
A Gentle Introduction to Data Science Presentation (Storytelling)
SQL Data Science: Most Common Queries all Data Scientists should know