
Exploratory Data Analysis (EDA) is an essential step in the data science project lifecycle. All data scientists have to do this step to get a better understanding of the data they are working on. In this article, I am going to share with you the top 10 Exploratory Data Analysis (EDA) Tools you can try to make this process easier and faster for you.
What is Exploratory Data Analysis aka EDA?
For those of you who do not know what exploratory data analysis (EDA) is, it is a term that appeared first in 1977 from a statistician name John W. Tukey. He defined it as “detective work - numerical detective work - or counting detective work - or graphical detective work”.
If like me, you were confused by the original definition, you can think of EDA as a process in which the data analyst analyses/examines/go through a dataset without having any preconceived idea as to what he/she is going to discover. The goal is to understand what the data is going to tell you about the studied topic. Let the data speak to you.
Practically, data scientists use this methodology to analyze, examine and summarize the main characteristics of their dataset. Indeed, it happens through summary information presented as insights and accompanied by various data visualization methods. The results of an EDA help a Data Scientist learn the best way to handle data sources to get the insights you need. Additionally, the whole process makes it easier to spot anomalies, test a hypothesis, discover patterns, or check assumptions.
EDA is essentially used to understand what data can show beyond the conventional hypothesis testing task. It gives a better understanding of the data variables and features, along with the relationships between them. It can also help determine if the statistical techniques considered for data analysis are suitable.
What do Data Scientist use as Tools for Exploratory Data Analysis (EDA)
A trained data scientist often does EDA through standard programming tools such as Python and Pandas. As technology advances, a few libraries were created to ease the process and save a lot of time writing repetitive code.
Below are few libraries that may make EDA faster and a bit more intuitive, especially if you are not a code-savvy person. Give them a try in your spare time, and let me know your favorite.
1. SweetViz
Sweetviz is one of my, if not my favorite, Exploratory data Analysis library. It is an open-source Python library that generates beautiful, high-density visualizations to kickstart the EDA (Exploratory Data Analysis) process with just two lines of code. The output is a self-contained HTML application.
The idea behind the system is quickly visualizing target values and comparing datasets. It aims to help quick analysis of training vs testing, data target characteristics, and other such data characterization tasks.
SweetViz Key Features
- Target analysis
- It shows you how a target value relates to other features.
- Type inference
- Automatically detects numerical, categorical, and text features with optional manual override.
- Numerical analysis:
- min/max/range, mean, mode, standard deviation, quartiles,
- sum, median absolute deviation, coefficient of variation, kurtosis, skewness
- Visualization and Comparaison
- Distinct datasets (e.g. training vs test data)
- Intra-set characteristics (e.g. male versus female)
- Mixed-type associations
- Integration of associations for numerical (Pearson’s correlation), categorical (uncertainty coefficient), and categorical-numerical (correlation ratio) datatypes seamlessly, to provide maximum information for all data types.
- Summary information
- Type, unique values, missing values, duplicate rows, most frequent values
For more information about SweetViz, check here.
2. Pandas Profiling
Pandas profiling is yet another EDA platform more often than not, the first one learners learn. It is as well the most popular too. Indeed, Pandas Profiling is relatively easy to use, to set up, and feels like an extension to your standard pandas library rather than a system of its own. It is easily integrable with your favorite tools(Jypyter & Collab), and there is extensive documentation on how to use the library. Additionally, there is a good community around this library that is ready to answer any questions you may have.
Pandas Profiling Key Features
- Type inference: detect the types of columns in a dataframe.
- Essentials: type, unique values, missing values
- Numerical analysis: minimum value, Q1, median, Q3, maximum, range, interquartile range, mean, mode, standard deviation, sum, median absolute deviation, coefficient of variation, kurtosis, skewness
- Most frequent values
- Histogram
- Correlations highlighting of highly correlated variables, Spearman, Pearson, and Kendall matrices
- Missing values matrix, count, heatmap, and dendrogram of missing values
- File and Image analysis: extract file sizes, creation dates, and dimensions and scan for trimmed images or those containing EXIF information.
- Text analysis learns about classes (Uppercase, Space), scripts (Latin, Cyrillic), and blocks (ASCII) of text data.
The main problem with Pandas Profiling is that it works very slowly with large datasets. You can solve this problem by generating a partial report that cuts down the heavy steps. Additionally, just like the name, Pandas-Profiling creates a profile of the dataset because
Read more about pandas profiling here.
3. Dataprep
Dataprep is one of the fastest EDA (Exploratory Data Analysis) tools in Python. It allows you to understand a Pandas/Dask DataFrame with a few lines of code in seconds. Indeed, Dataprep allows the user to explore features/characteristics of a dataset through simple APIs. The awesome part about it is that you can go through a dataset from a high level to a low level, allowing you to test different perspectives.
According to the Authors, Data prep has:
- 10-100X Faster: DataPrep.EDA is 10-100X faster than Pandas-based profiling tools due to its highly optimized Dask-based computing module.
- Interactive Visualization: DataPrep.EDA generates interactive visualizations in a report, which makes the report look more appealing to end-users.
- Big Data Support: DataPrep.EDA naturally supports big data stored in a Dask cluster by accepting a Dask dataframe as input.
Dataprep Key Features
- Dataset Descriptive statistics.
- Columns Distribution Analysis: detect the column type and then output various plots and statistics that are appropriate for the respective type.
- Correlations: explores the correlation between columns in various ways and using multiple correlation metrics.
- Missing values: generate various plots which display the number of missing values for each column and any underlying patterns of the missing values in the dataset.
If you want more information about DataPrep, you can check them out here.
4. D-tale
D-Tale is the combination of a Flask backend and a React front-end to bring you an easy way to view & analyze Pandas data structures. It integrates seamlessly with ipython notebooks & python/ipython terminals. Currently, this tool supports such Pandas objects as DataFrame, Series, MultiIndex, DatetimeIndex & RangeIndex.
D-Tale is, based in my opinion, one of the best EDA libraries out there. It outshines the other based on the level of customizations that are available within the library. In other words, it fulfills the purpose of Exploratory Data Analysis since you can go deep and explore all the details in your dataset. . It features a code export to regenerate/recreate any plot or analysis made during the exploration.
D-Tale Key Features:
- A full exploration navigation system
- Overview of dataset
- Code export
- Custom filters
- Correlation, Charts, and Heatmaps
- Highlight datatypes, missing values, ranges
The only downside you can have is that there is a small learning curve since the library has many options. Usually, a trained data scientist will be able to use it after an hour or two.
If you want to know the full set of features for D-Tale, please check this link.
5. Pandas GUI
PandasGUI, as the name suggests, is a graphical user interface for analyzing Pandas’ dataframes. The project is still in the development phase. Ergo, it can be subject to breaking changes, sometimes. However, from an EDA perspective, PandasGUI comes with many useful features. Using it feels like you are doing the same type of exploration when you are coding, but just through a Graphical Use Interface. It is very good when you try to illustrate your cleaning steps to someone who is not comfortable reading code.
Pandas GUI Key Features
- View DataFrames and Series (with MultiIndex support)
- Interactive plotting
- Filtering through Query expressions
- Statistics summary
- Data editing and copy/paste
- Import CSV files with drag & drop
- Search toolbar
To get the full set of features for Pandas GUI, please refer to their official page here.
6. Bamboolib
Bamboolib allows you to analyze data in Python without having to write code. It is one of the most intuitive libraries out there and is made of a good set of features for data exploration.
You can easily illustrate your work to someone who can’t code. Indeed, it allows team members of all skill levels to cooperate within Jupyter and to share the working results as reproducible code.
If you are an employer, using this library can reduce employee onboarding time and training costs.
As opposed to the other libraries here, Bamboolib has a paid and a community version. The community version is complete so you should not have any trouble using it.
Bamboolib Key Features
- Intuitive GUI that exports Python code
- Supports all common transformations and visualizations
- Provides best-practice analyses for data exploration
- Can be arbitrarily customized via simple Python plugins
- Integrate any internal or external Python library
To get the full set of features for Bamboolib, please refer to their official page here.
7. AutoViz
Even though it is not as feature-rich as the other libraries, AutoViz allows you to perform automatic visualization. With this library, you can plot all the relevant relationships between the different features with one line of code, no matter the type of dataset you have.
On a very large dataset, AutoViz will take a random sample from the file. Additionally, if you have too many features (columns), AutoViz can select the features that are the most important and plot them.
This library is great if you want to get a quick idea about the relationships between the different features. I usually use it first to understand the dynamics and relationships within a dataset, if I am in a hurry. If you have 15 mins to drive quick insights from a dataset, then use AutoVis.
AutoVis Key Features
The use of Autovis is simple
- Scatter Plot of each Continuous Variable against Target Variable
- Pairwise Scatter Plot of each Continuous Variable against other Continuous Variables
- Histogram Plots of all Continuous Variable
- Violin Plots of all Continuous Variable
- Distribution Plot of Target Variable
- Heatmap of all Continuous Variables for target Variable
- Bar Plots of Average of each Continuous Variable by Target Variable
- Time Series Plots of Two Continuous Variables against a Date/Time Variable
The main disadvantage of this library is that it is not a full EDA library. Indeed, It does not do anything else other than creating plots quickly, which in some cases saves a lot of time.
Checkout the full set of features in their official website by following this link.
8. Dora
Dora is a Python library designed to automate the difficult and inconvenient parts of exploratory data analysis. The library contains helper functions for data cleaning, feature selection & extraction, data visualization, partitioning data for model validation, and versioning transformations of data. The library uses and is intended to be a helpful addition to common Python data analysis tools such as pandas, scikit-learn, and matplotlib.
This library is not as intuitive as the other ones in this article and you should most definitely know how to code to use it. You can think of this library as a couple of additional repetitive functions that you use to write in every EDA Project. Dora wrote those functions for you. All you have to do is call them and analyze the results.
Dora’s Key Features
- Reading Data & Configuration
- Cleaning
- Feature Selection & Extraction
- Visualization
- Model Validation
- Data Versioning
You can check out the full set of feature in the Dora’s official documentation available here.
9. Visidata
VisiData is an interactive multitool for tabular data. It combines the clarity of a spreadsheet, the efficiency of the terminal, and the power of Python, into a lightweight utility that can handle millions of rows with ease.
This library is perfect if you want to do EDA on a terminal. Analyzing data on the terminal is not the most convenient of things. But, if you have a project that requires it, think of using Visidata for your EDA.
Visidata key features:
- Editing contents
- Grouping data and descriptive statistics
- Creating sheets, rows, and columns
- Combining datasets
- Drawing graphs
- How to save and replay a VisiData session
10. Scattertext
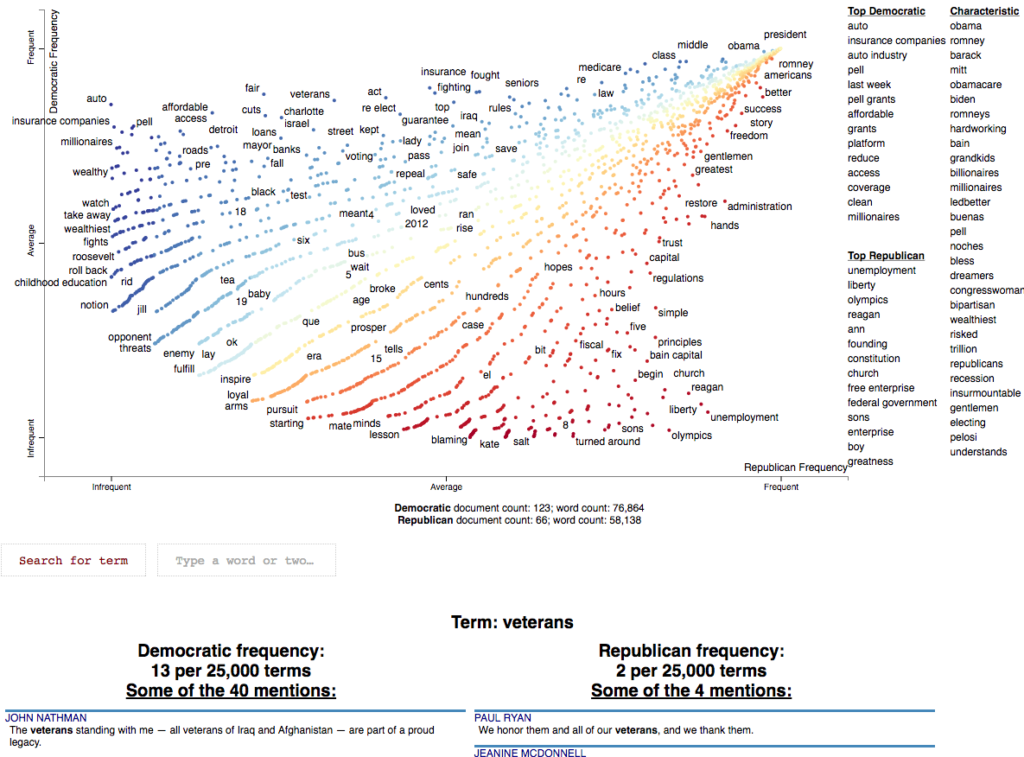
If you want to do EDA on a Natural Language Processing (NLP) project, then you may want to use Scattertext. It is a tool for finding and distinguishing terms in corpora and presenting them in an interactive HTML scatter plot. The various points relate to terms that are selectively labeled so that they don’t overlap with other labels or points.
This library again is not a full EDA system, so you will need to know how to code to use it. Even though it is not a full edge EDA platform, the visualization within Scattertext allows you to give context to your NLP project. They are clean, understandable, well presented, and interactive, allowing you to better present the data you have.
Scattertext Key Features:
- Using Scattertext as a text analysis library: finding characteristic terms and their associations
- Visualizing term associations and phrase associations
- Visualizing Empath topics and categories
- Displaying the Moral Foundations 2.0 Dictionary
- Ordering Terms by Corpus Characteristicness
- Document-Based Scatterplots
- Using Cohen’s d or Hedge’s r to visualize effect size
You can check the full set of feature that Scattertext has in their official website available here.
Conclusion
Exploratory data analysis is an iterative cycle with steps including
- Investigating the data
- Solving your hypothesis by processing and visualizing the data
- Refining previous hypothesis after getting a new understanding of the dataset, or new perspective on your hypothesis
In one sentence. Let the data speak to you. There is no one-size-fits-all methodology and tools that are suitable for all EDA. It varies from project to project, and it is up to you to figure out what tools allow you to go through the EDA process comfortably.
Let me know what is your favorite tools down below.
Need this on your data, not a demo dataset?
Tutorials run on clean example data. Production data doesn’t cooperate. When forecasting, segmentation, churn, or LTV modelling has to survive real, messy data and drive an actual decision, that’s data science consulting work. Book a call and tell me what you’re trying to predict.
Feel free to use any information from this page. I’d appreciate it if you can simply link to this article as the source. If you have any additional questions, you can reach out to malick@malicksarr.com. If you want more content like this, join my email list to receive the latest articles. I promise I do not spam.
If you liked this article, maybe you will like these too.
Why is Machine Learning important? [in 2021]